Searching a static web site with Azure AI Search and semantic search - part 1
Learn how to fully automate an Azure AI search instance that pulls data and indexes it from an Azure Blob Storage account

Azure AI Search (previously Azure Cognitive Search) is a powerful search engine that provides full text search amongst other features.
In this blog post we'll go through:
- Setting up Azure AI search and related resources with terraform
In the next blog post we'll go through:
- Extracting static pages and processing them
- Uploading the static pages to a storage account
- Indexing the static pages in Azure AI search
- Searching the pages
Getting started
Create a git repository to work from:
mkdir azure-ai-search-terraform
cd azure-ai-search-terraform
git initSetting up the repository
Now we need to setup the terraform providers we need, create a file called providers.tf:
terraform {
# backend "azurerm" {} # uncomment to store the state file in Azure
required_providers {
azurerm = {
source = "hashicorp/azurerm"
}
restapi = {
source = "Mastercard/restapi"
}
}
}
provider "azurerm" {
features {}
}providers.tf
The AzureRM provider will be used to create most of the resources, the Mastercard/restapi provider is used to configure Azure AI Search as there is currently no built in provider that can manage Azure AI Search resources after its creation, (see this issue from 2021).
After creating the providers file lets init terraform:
terraform initYou should see output that looks like:
Terraform has been successfully initialized!
You may now begin working with Terraform. Try running "terraform plan" to see
any changes that are required for your infrastructure. All Terraform commands
should now work.
If you ever set or change modules or backend configuration for Terraform,
rerun this command to reinitialize your working directory. If you forget, other
commands will detect it and remind you to do so if necessary.The resources
First we'll create a resource group:
resource "azurerm_resource_group" "this" {
location = "UK South"
name = "example"
}
resource-group.tf
A storage account that we will use to store the data in part 2:
resource "azurerm_storage_account" "default" {
name = "yourstorageaccountname" # replace me
location = azurerm_resource_group.this.location
resource_group_name = azurerm_resource_group.this.name
account_tier = "Standard"
account_replication_type = "LRS"
allow_nested_items_to_be_public = false
# Required so the indexer can detect deleted files
blob_properties {
delete_retention_policy {
days = 7
}
container_delete_retention_policy {
days = 7
}
}
}
resource "azurerm_storage_container" "example" {
name = "example"
storage_account_name = azurerm_storage_account.default.name
}
data "azurerm_client_config" "current" {}
# permission for logged in user to upload to the storage account
resource "azurerm_role_assignment" "storage_blob_data_contributor_user" {
principal_id = data.azurerm_client_config.current.object_id
scope = azurerm_storage_account.default.id
role_definition_name = "Storage Blob Data Contributor"
}
storage.tf
Then a search service:
resource "azurerm_search_service" "this" {
name = "your-search-service" # replace-me
resource_group_name = azurerm_resource_group.this.name
location = azurerm_resource_group.this.location
sku = "basic"
replica_count = 1
partition_count = 1
# Allow key auth to be used for the restapi provider
local_authentication_enabled = true
# Enable RBAC auth for the most secure authentication for the application
authentication_failure_mode = "http403"
semantic_search_sku = "standard"
identity {
type = "SystemAssigned"
}
}
# permission for search service to access the storage account
resource "azurerm_role_assignment" "storage_blob_data_reader_search_service" {
principal_id = azurerm_search_service.this.identity[0].principal_id
scope = azurerm_storage_account.default.id
role_definition_name = "Storage Blob Data Reader"
}search.tf
Now that we've created the search service we can configure the restapi provider that we'll need in a minute, update the providers.tf file adding this to the bottom:
provider "restapi" {
uri = "https://${azurerm_search_service.this.name}.search.windows.net"
write_returns_object = true
headers = {
"api-key" = azurerm_search_service.this.primary_key,
"Content-Type" = "application/json"
}
}
providers.tf
To store the data we'll need an index,
We'll pull in a few fields that are auto generated by the indexer:
metadata_storage_name- name of the filemetadata_storage_path- full storage path including the storage account namemetadata_storage_content_md5- used to see if the file has changed for indexingcontent- the text content that has been extracted from the source filetitle- a metadata attribute that will be set on the file in part 2
locals {
index_json = {
name = "example"
fields = [
{
name = "id"
type = "Edm.String"
searchable = false
filterable = false
sortable = false
key = true
facetable = false
},
{
name = "metadata_storage_last_modified"
type = "Edm.DateTimeOffset"
searchable = false
filterable = true
sortable = false
facetable = false
},
{
name = "title"
type = "Edm.String"
searchable = true
filterable = true
sortable = true
facetable = false
},
{
name = "metadata_storage_name"
type = "Edm.String"
searchable = true
filterable = true
sortable = true
facetable = false
},
{
name = "metadata_storage_path"
type = "Edm.String"
searchable = true
filterable = true
sortable = true
facetable = false
},
{
name = "metadata_storage_content_md5"
type = "Edm.String"
filterable = true
sortable = true
facetable = false
},
{
name = "content"
type = "Edm.String"
searchable = true
filterable = false
sortable = false
facetable = false
},
],
semantic = {
configurations = [
{
name : "example",
prioritizedFields = {
titleField = {
fieldName = "title"
},
prioritizedContentFields = [
{
fieldName = "content"
}
],
prioritizedKeywordsFields = []
}
}
]
},
}
}
# See: https://learn.microsoft.com/en-us/rest/api/searchservice/preview-api/create-or-update-index
resource "restapi_object" "index" {
path = "/indexes"
query_string = "api-version=2023-10-01-Preview"
data = jsonencode(local.index_json)
id_attribute = "name" # The ID field on the response
}
index.tf
We've configured a semantic search configuration which will provide a secondary ranking of the result using language understanding to reevaluate the result set.
Now that we've defined an index, we need a datasource that an indexer can pull from:
locals {
datasource_json = {
name : "example",
description : "Example datasource",
type : "azureblob",
credentials : {
connectionString : "ResourceId=${azurerm_storage_account.default.id};"
},
container : {
name : "example",
},
dataDeletionDetectionPolicy : {
"@odata.type" : "#Microsoft.Azure.Search.NativeBlobSoftDeleteDeletionDetectionPolicy",
},
}
}
# https://learn.microsoft.com/en-us/rest/api/searchservice/create-data-source
resource "restapi_object" "storage_account_datasource" {
path = "/datasources"
query_string = "api-version=2023-10-01-Preview"
data = jsonencode(local.datasource_json)
id_attribute = "name" # The ID field on the response
depends_on = [
azurerm_search_service.this,
azurerm_role_assignment.storage_blob_data_reader_search_service
]
}
datasource.tf
Notice that there's a data deletion policy based off of native blob soft delete, we configured that earlier in the storage account retention configuration, if files are deleted, they will be deleted from the index as well.
Also see that there's no credentials required to access the storage account, thats because the system assigned managed identity of the search service is accessing it using Azure RBAC with the 'Storage Blob Data Reader' role.
Finally we will create an indexer that will extract the files from the storage account:
locals {
indexer_json = {
name : "example",
dataSourceName : "example",
targetIndexName : "example",
parameters : {
configuration : {
indexedFileNameExtensions : ".html",
imageAction : "none"
}
}
}
}
// https://learn.microsoft.com/en-us/rest/api/searchservice/preview-api/create-or-update-indexer
resource "restapi_object" "indexer" {
path = "/indexers"
query_string = "api-version=2023-10-01-Preview"
data = jsonencode(local.indexer_json)
id_attribute = "name" # The ID field on the response
depends_on = [azurerm_search_service.this, restapi_object.index, restapi_object.storage_account_datasource]
}
indexer.tf
You will see that there's no schedule configured, that's because this example is for a static site, we'll trigger the indexer in part 2 using the API as part of the static site deployment so there's no need to schedule it.
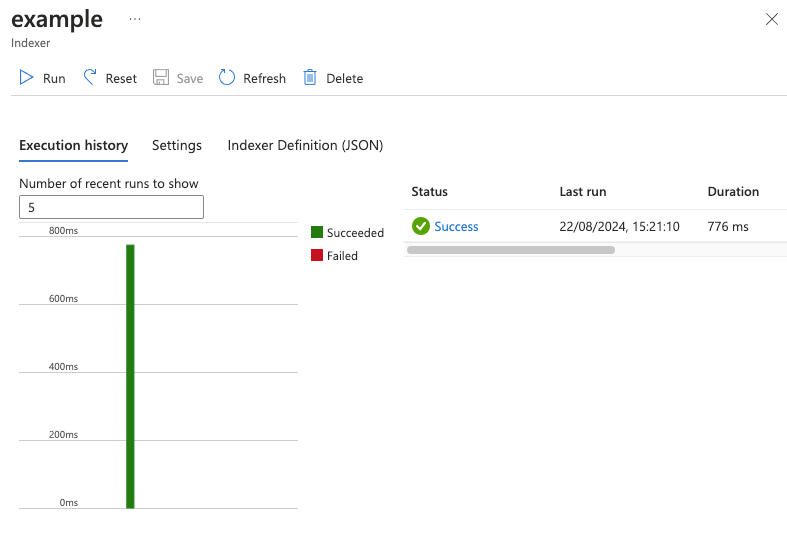
You should be able to run the indexer now and get a successful run it will just import 0 documents.
Click the run button in the top left and if everything has worked you should get a success:
For a complete reference of all the code used in this blog please see:
 timja
timja